





The generators represent a quite powerful conception of gradually consumed
(and sometimes infinite) streams of data. Almost every Python 3.x developer
has encountered generators when used range or zip methods. However, the
generators could be used not only as the sources of data but also as
coroutines organized into data transformation chains. This post shows how to
build a generators-based data pipeline processing the images from an external storage.
Disclamer: This post is mostly about the one specific use case of the Python generators --- transforming arrays of data passing them from one coroutine to another. For more rigorous introduction into generators and coroutines please refer the links at the bottom of this page.
Post contents
Generators and Yield Keyword
Every programming language supports a conception of data arrays or lists. The list is a sequence of elements stored in the memory during program execution which elements are directly accessed using integer indexes.
The crucial difference between generators and lists is that it does not provide
a random access to its elements and does not keep them in memory. Moreover, in
general, it doesn’t know in advance how many elements will be produced. It
can only yield the results one by one, when next() function or method is called.
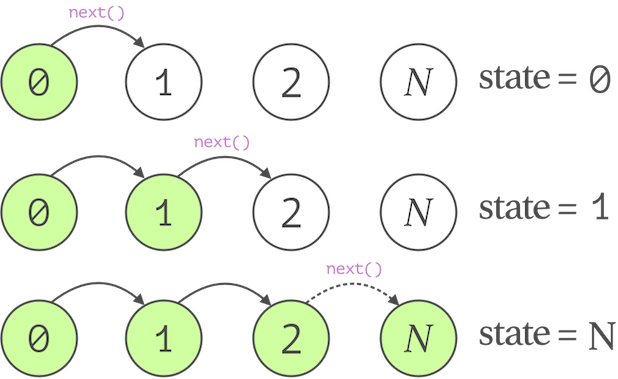
Conceptually, a generator could be thought of as a sort of state machine
that changes its state on demand and produces the new elements while moving from
one state into another. Talking about implementation of this concept, the Python
language provides a very simple way to create such objects. You need to use a special
keyword yield instead of return in the function definition, and this function
will be treated as a generator. In other words – as an ojbect that doesn’t just
return a single value on its invocation but memorizes the state after each call
and produces the new values depending on that state.
As it was mentioned, the generators do not store in the memory the whole sequence of their values. This property could be especially helpful when the length of a sequence is not known in advance. One of the most straightforward examples of such sequence is a mathematical series like Catalan numbers which could be implemented as the following snippet shows.
def catalan(start=0):
from math import factorial
n = start
while True:
next_number = factorial(2*n)//factorial(n + 1)//factorial(n)
yield next_number
n += 1
Therefore, the generators provide a simple API to implement a stateful object
that tracks the progress and creates the new elements depending on the previous
calls. When the function catalan is called the first time, the body of the
function is executed until the first occurrence of the yield keyword.
In order to continue generator’s execution and retrieve the produced values, one could:
- Use the
nextbuilt-in to get a single value from the generator - Pass generator object into a sequence constructor like
list - Use
for-inloop (which implicitly callsnexton every iteration) to iterate over all available elements
Here is an example of creating a generator and retrieving its values.
from itertools import islice
# create generator
catalan_numbers = catalan()
first_5_numbers = [next(catalan_numbers) for _ in range(5)]
assert first_5_numbers == [1, 1, 2, 5, 14]
next_5_numbers = list(islice(catalan_numbers, 0, 5))
assert next_5_numbers == [42, 132, 429, 1430, 4862]
So far nothing different from usual lists, except that the generator yields data in chunks that are consumed by the caller. The generators though can not only return the values, but also receive them from the “outside”. It allows you to modify its behavior in the runtime. The next section explains how.
Sending Values into Generator
The special method send() allows to pass a value into the generator. This
method allows treating it as a coroutine, or in other words – a supplementary
program with its own computational state which is executed asynchronously.
(Please refer the following link to find out a more
rigorous definition of coroutine).
Consider the following use case. You have a list of file names generated while training a machine learning model. Some of them contain intermediate model’s weights computed during training. Every of these files contains relevant validation loss in their names. We want to iterate through these files and extract the loss values using a regular expression. All files that don’t match should be ignored. The following snippet shows how this goal could be achieved using a generating function.
"""
Simple example shows usage of generators as coroutines accepting values from
outside and yield processed values to caller.
"""
import re
def get_loss(regex='^[\d\w]+(\d.\d+).hdf5$'):
"""
Checks if the name of a file with the model's weights matches the regular
expression and returns a numerical value of the loss.
Otherwise, None is returned.
"""
reg = re.compile(regex)
while True:
filename = yield
match = reg.match(filename)
result = None if match is None else float(match.group(1))
yield result
def apply(gen, item):
"""Advance generator to the next yield statement and send a value."""
gen.send(None)
result = gen.send(item)
return result
def main():
filenames = [
'model.h5',
'checkpoint',
'weights_1.042.hdf5',
'log.txt',
'weights_bs128_0.984.hdf5',
'weights_resnet_val_loss_0.209.hdf5']
gen = get_loss()
for filename in filenames:
result = apply(gen, filename)
if not result:
continue
print(result)
if __name__ == '__main__':
main()
The get_loss() function call creates a generator with the default regex string.
Then we iterate over file names and send them into the newly created generator one
by one. If the returned value is not None, we print the extracted
loss. Also note how we use the apply() function. Every newly created generator
should accept None as its first sent value. Because there are two yield statements
in the generator, we continue sending None before sending an actual value to
advance the generator’s state to an appropriate line of execution. Generally speaking,
each send() call advances the generator to the next yield, and returns the value
from the right side of that statement.
It means that instead of having all logic inside of single program or creating the stateful objects with their own attributes and properties, we can create a group of generators passing the data from one to another sequentially.
The shown example is quite simple and can be easily implemented in more straightforward fashion, like creating a simple filtering function without any additional sophistication. The following section shows a more involved example of building a group of generators organized into the data processing pipeline that helps to decrease the amount of consumed memory to process the dataset of images iteratively.
Images Processing Pipeline
Let’s consider the following example. You have a dataset with labeled images and want to train an image classifier. You are going to use some form of Stochastic Gradient Descent, that trains a model in batches instead of running the optimization algorithm on the whole dataset. On every training batch, the following preprocessing steps should be performed before the batch could be used in the training process:
- Crop the images and convert them into a NumPy array
- Apply the data augmentation transformations
- Re-scale samples into a range of values expected by the model
- Shuffle the batch samples to randomize training process
You could read all the available images into memory, apply preprocessing steps and start training by feeding one training batch after another into the optimization algorithm. However, even a reasonably small dataset of so 10,000 – 20,000 samples will easily occupy several dozens of gigabytes of RAM when is read from the file system into NumPy arrays.
Let’s pretend that each image has a resolution of 256x256 pixels and three color channels.
When loaded into memory as a 3D array of uint8 numbers, the image will take
$$ 256 \times 256 \times 3 \times 8 = 1.5 \mathrm{Mb} $$
It means that dataset of 10000 images will occupy $\approx14.6\mathrm{Gb}$ of memory. Even if you have enough space to load all these files at once, your system could slow down or raise an out-of-memory error later during the next steps. Also, the data augmentation process is performed on the fly and cannot be cached so you can’t save the prepared data back onto the disk and read sample by sample. Therefore, in most cases reading all available files into memory or caching the preprocessed data is not a flexible solution.
An alternative approach is to read the images gradually in small chunks, converting every of them into the expected representation, and sending them into the training algorithm afterwards. To achieve this goal, you can create a group of generators where every of them is expecting an $(x, y)$ pair with the images and labels, applies transformations, and yields it to the next transformer in the chain.
TL;DR:Here is the full source code of the described example. Please note that the following examples of the code were modified to keep them simple enough.
The very first generator in the pipeline should discover the image files in a folder,
match the file path with its label, and convert the labels from a verbose representation
into one-hot encoded vectors
that are feasible for the most of the optimization algorithms. For this purpose, LabelBinarizer class from
scikit-learn package could be used.
The generator expects images to be organized into sub-folders where every sub-folder’s name is the name of a class where the images from this sub-folder belong to.
$ tree images
images
├── airedale
│ ├── 02c90d8109d9a48739b9887349d92b1f.jpg
│ ├── 07ddc3c2188164b1e72ae6615a24419a.jpg
├── boxer
│ ├── 008887054b18ba3c7601792b6a453cc3.jpg
│ ├── 0e3cdff3560de43a8aa1d9820c211fae.jpg
│ ├── 1831f3ce615ffe27a78c5baa362ac677.jpg
├── golden_retriever
│ ├── 0021f9ceb3235effd7fcde7f7538ed62.jpg
│ ├── 2ae784251c577222be8f7f3cef36e2d0.jpg
...
The function dataset() implements the logic described above and produces $(paths, labels)$
pairs where every element of a pair has the length of batch_size. Every next() call will
produce a new batch of the data. Note that on this step no images are stored in the memory,
only their paths, and labels. Therefore, when a generator is created, it occupies
a very small amount of memory.
from math import ceil
from sklearn.preprocessing import LabelBinarizer
def dataset(root_folder, batch_size=32):
images_and_labels = list(discover_images(root_folder))
n_batches = int(ceil(len(images_and_classes) / batch_size))
classes = [c for (img, c) in images_and_classes]
binarizer = LabelBinarizer().fit(classes)
start = 0
for _ in range(n_batches):
batch = images_and_classes[start:(start + batch_size)]
paths, labels = zip(*batch)
encoded = binarizer.transform(labels)
start += batch_size
yield np.asarray(paths), encoded
Function discover_images() could be implemented as a generator itself to save
a couple of lines required to create a buffer list to store every discovered
file and label pair before returning them to the caller:
from os import listdir
from os.path import join
def discover_images(folder):
for image_class in listdir(root_folder):
subfolder = join(root_folder, image_class)
for sample in listdir(subfolder):
filename = join(subfolder, sample)
yield filename, image_class
Next, we need a generator accepting the discovered files paths, reading them into
memory, resizing to the shape expected by a model and converting them into a NumPy array.
If the previously created function could be treated as a preparation step gathering the
meta-information required to create the training samples and targets, the read_images()
generator defined below actually reads the data from an external storage into the memory.
But still, it will not read into the memory more files than were sent by the previous step
in the chain, keeping an amount of the occupied space reasonably small.
To read and resize the image file, we use the Pillow library and the following snippet that is almost completely copied from this Keras’s utility function.
def read_images(target_size=(224, 224)):
while True:
filenames, y = yield
images = []
for sample in filenames:
img = Image.open(sample)
if img.mode != 'RGB':
img = img.convert('RGB')
img = img.resize(target_size, Image.NEAREST)
images.append(img)
yield images, y
Other steps are implemented in the similar fashion as the snippet shows.
But the main idea is the same – you need a function with two yield statements:
the first one to receive initial value, and the second one – to produce the output.
Note that you can do it simultaneously like a = yield b, but in this case an initial
value of b should be precomputed within the generator’s definition.
How to gather all these things together? The only thing you need is to create a list of your generators and write a simple loop receiving the output from the previous generator and sending it to the next one.
The following class called GeneratorPipeline shows one possible solution that
expects a “source” generator and a list of “transformers” where every generator
has two yield statements in their definitions.
class GeneratorPipeline:
def __init__(self, source, *steps):
self.source = source
self.steps = list(steps)
def __iter__(self):
return self
def __next__(self):
return self.next()
def next(self):
batch = next(self.source)
self.send_none()
transformed = self.send(batch)
return transformed
def send_none(self):
for step in self.steps:
step.send(None)
def send(self, batch):
x = batch
for generator in self.steps:
x = generator.send(x)
return x
Finally, there is a snippet below that schematically shows how to use the created classes and generators to optimize model using batch by batch training.
Note the two magic methods in the GeneratorPipeline implementation, namely, __iter__ and __next__.
Both are required to make the class’s instances compatible with the iterable interface.
That interface is required if you want to use the objects of the class in for-in loops,
list comprehensions or any other contexts where the iterables are used. Due to the dynamical
nature of the Python language, there is no need to implicitly inherit any classes, only to provide
an implementation of the required magic methods.
As it was mentioned previously, for-in loop automatically calls __next__ method of
a pipeline object and receives the batches of the training data:
# chain generators together
pipeline = GeneratorPipeline(
dataset('/path/to/images'),
read_images(),
augment(rotate90=True),
rescale_images(mean=[103.939, 116.779, 123.68]),
shuffle_samples())
# build model
model = create_model()
# start training
for x_batch, y_batch in pipeline:
model.train_on_batch(x_batch, y_batch)
Therefore, from a syntactical point of view, the pipeline is not really different from using any standard Python’s collection. Though there is a big difference from the semantical perspective. The provided code doesn’t read all images into memory but instead processes them gradually and applies all the required modifications on the fly. Also, one could easily replace any part of the pipeline with a different implementation, or switch data source from the local files to a network connection, database or anything else.
More about Generators
David Beazley has a great series of tutorials showing how powerful the conception of generators is. As one of the examples, the author shows a development of simple tasks scheduler similar to the one that is used by OS to allocate CPU time among the concurrent processes. Fluent Python by Luciano Ramalho is a great book discussing different Python’s topics, and generators/coroutines are among them.
The most recent versions of Python include asynchronous features and coroutines into the language as first-class citizens. Please refer to the Python documentation to learn more.
Conclusion
When processing the huge amounts of data, it is not always possible to read everything into memory at the beginning of the program’s execution. Moreover, sometimes it is not even required. In the case of deep learning models training, you usually use a GPU to optimize the network which in many cases can’t fit all the data samples into its memory and runs the training algorithm in batches.
Python’s generators provide a simple API to create the stateful objects that memorize the results of their previous calls and use this information to produce the next values. This abstraction allows implementing coroutines and data streams, helping to make the programs modular, simple to understand and memory efficient.
Other possible use cases include reading the data from remote data sources, reading the real-time signals that cannot be cached, or produce all the values in advance, and many more different situations when the asynchronous execution is required.